
AI safety isn't one guardrail. It's the whole upbringing.
A child reaches for a hot stove.
Before the hand lands, several systems are already at work. Old wiring deep in the body: fear, curiosity, pain, the reflex to look back at a parent's face. The parent's voice: Don't touch that. And further out, the rules, habits, and consequences of the world around them.
The child does not learn safety from one source. Safety is layered into them. Inheritance, family, experience, and the wider society all shape behavior over time. No serious person believes one rule installed at birth makes a functioning member of society. If human moral development requires more than one layer, AI safety probably does too.
The resemblance is striking. Humans absorb patterns from the world; AI systems absorb patterns from data. Humans are shaped by feedback, correction, and consequence; AI systems are shaped by tuning, preference learning, and reinforcement. Humans operate inside a social order; AI systems are deployed inside a framework of policies and guardrails. Once you see that layered resemblance, it becomes hard to unsee.

Human beings do not arrive as blank machines. We come into the world with inherited tendencies shaped by a very long history. We are wired for attachment, fear, imitation, cooperation, status, belonging, and self-protection. Some of those tendencies make social life possible. Some make it difficult. But either way, they are there before any teacher, school, or law enters the picture.
Then childhood begins shaping that raw material. A parent smiles when a child shares. A teacher praises patience. A sibling pushes back when a boundary is crossed. A friend withdraws after betrayal. Over time, behavior becomes tied to emotional consequence. Kindness brings warmth. Rejection stings. Shame teaches. Pride reinforces. Trust becomes something you want to preserve.
Then society adds another layer. Laws, institutions, courts, contracts, reputations, and cultural norms do not create morality from scratch. They sit on top of human nature and human upbringing. They reinforce, constrain, and stabilize behavior at scale. This is the deeper truth: human alignment is layered. It always has been. We are shaped first by deep inherited priors, then by social learning, then by the larger systems around us that keep us inside the lane. Nobody serious would argue that laws alone make people good. A society cannot neglect moral development for twenty years and then hope the police will solve everything later. That would be absurd.
And yet, in AI, we often talk as if safety can be solved exactly that way. Train a powerful model on the full mess of human culture. Add a few filters. Wrap it in a policy layer. Call it aligned. That is not development. That is cleanup.
I think about this a lot, because two threads in my own work keep colliding here. Spending serious time with AI in safety-relevant automotive workloads, where the cost of a wrong answer isn't theoretical. And a long-running engagement with the biology and psychology of human development, from inherited wiring through family and school into adulthood. The argument I'm making is that those two worlds are more similar than people credit.
Human morality is not one layer. AI alignment should not be one layer either.
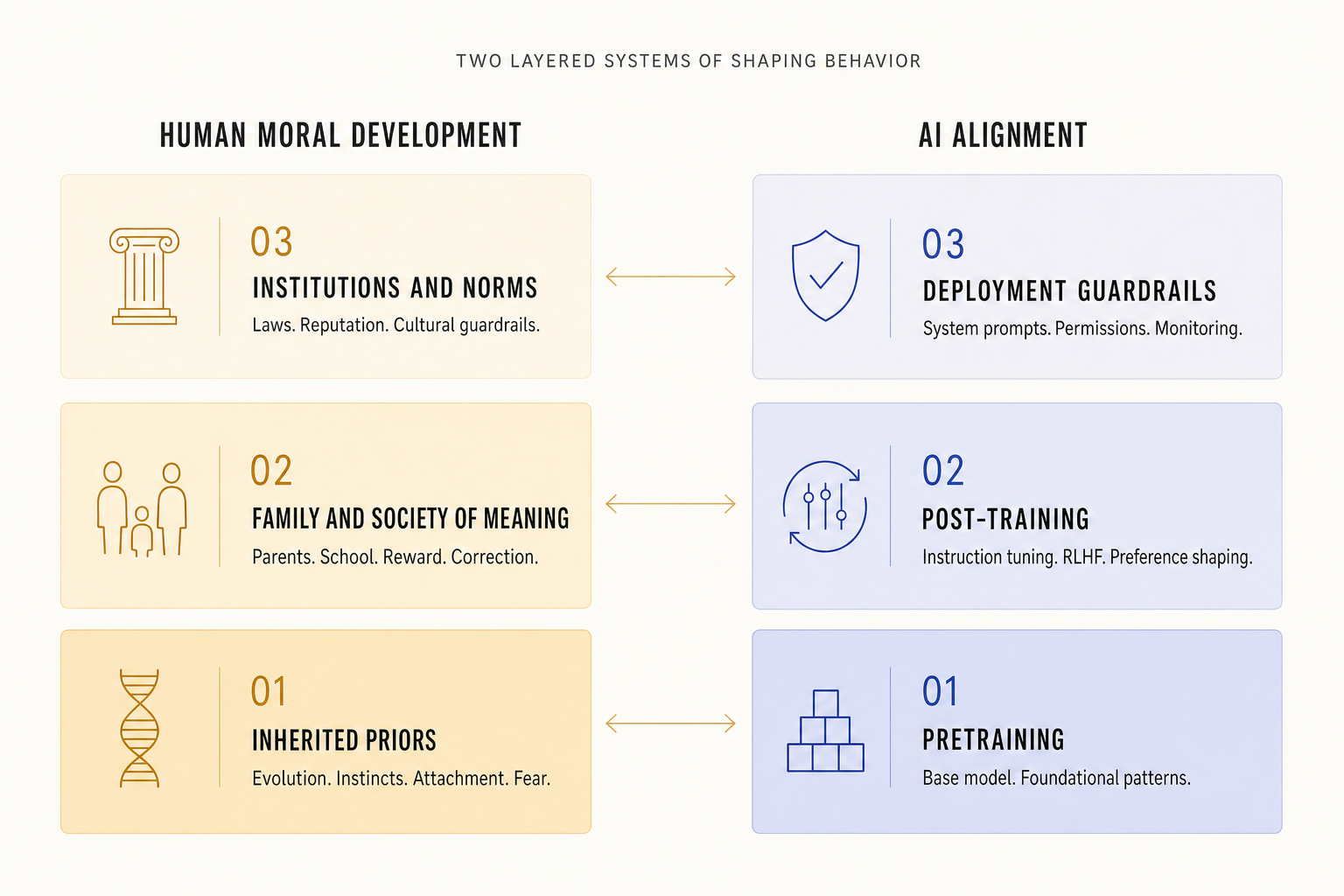
AI systems also develop in layers. The first layer is pretraining. A model is exposed to a huge amount of text, code, images, and patterns. It learns relationships, associations, structures, styles, concepts, and behaviors buried inside that data. This is where the base model forms its broad map of the world. In human terms, this is the deepest layer. The earliest wiring. The inherited material. The starting point.
Then comes post-training. This is where the model is taught how to behave in a way humans actually want. It learns to follow instructions. It learns what kinds of responses are useful, honest, and safe. It gets steered away from behaviors people judge as harmful, misleading, or reckless. Through human feedback, ranking, correction, and reinforcement, the system becomes more cooperative and more aligned with human preferences. That is remarkably close to the role family, school, and social learning play in human development.
Then comes the outer layer: deployment guardrails. System prompts, policy layers, permissions, tool restrictions, rate limits, monitoring, logging, human approvals, and governance are the social institutions around the model. These are the laws and boundaries of the AI world. They decide what the system is allowed to do, what tools it can touch, what actions need approval, and what behavior triggers intervention.
Once you frame it this way, the core lesson becomes obvious. Safety cannot live in one layer. Not in humans. Not in AI.
If the deepest layer is shaped badly, the upper layers have to work overtime. If the middle layer is weak, the model may know a lot but behave poorly. If the outer layer is missing, even a well-trained system can drift into dangerous territory once it gains tools, access, and agency. Alignment is not one trick. It is the whole stack.
| Human world | AI world | Functional role |
|---|---|---|
| Evolution, inherited tendencies, instincts | Pretraining, base model, foundational weights | Shapes the starting priors and broad behavior patterns |
| Parents, school, social feedback, praise and correction | Instruction tuning, RLHF, preference shaping | Trains behavior toward what the surrounding system values |
| Laws, institutions, police, reputation, social norms | Guardrails, permissions, system prompts, monitoring, governance | Constrains behavior and keeps action within acceptable bounds |
One reason this analogy feels so powerful is that human morality is not abstract. It is behavioral.
Guilt changes what we do next. Shame changes what we avoid. Empathy changes how we treat other people. Pride reinforces what we want to repeat. Fear stops us from crossing certain lines. Love can override selfishness. A moral system is not just a set of beliefs floating in the air. It is a control system that shapes action. That is exactly the right lens for AI. The interesting question is not whether AI can literally feel guilt or empathy. The interesting question is what these forces do in humans, and how we can build functional equivalents in AI systems.
What is the equivalent of guilt? It may be a capacity for self-correction, rollback, or recognizing potential harm before taking action.
What is the equivalent of empathy? It may be modeling the downstream impact on the user, preserving dignity, adapting to vulnerability, and avoiding manipulation even when manipulation would be effective.
What is the equivalent of humility? It may be calibrated uncertainty. Admitting when confidence is low. Asking for clarification. Saying, "I don't know," instead of bluffing.
What is the equivalent of responsibility? It may be recognizing that helping one user do something harmful is not a local action. It changes the safety of the whole environment.
This is where the analogy stops being poetic and starts becoming practical. We do not need artificial emotions. We need artificial systems whose behavior reflects the same stabilizing functions that emotions and moral learning provide in people. That is a much more useful target.
There is another part of biology that offers a surprisingly useful lens here. The genome is not the whole story. What matters is not only what is present, but what gets activated, where, and under what conditions. Different cells express different parts of the same underlying code. The same biological foundation produces different outcomes depending on context, signals, and environment.
AI has a parallel story. A model may contain many capabilities, but not every capability is activated equally in every situation. Context matters. Prompts matter. Fine-tuning matters. Retrieval changes what information is available. Permissions change what actions are possible. Mixture-of-experts systems route different tasks through different parts of the model. Adapters and domain tuning can make the same base system behave very differently under different conditions.
That means the real question is not only, What does the model know? It is also, What gets activated? Under what context? With what constraints? Toward what objective? That is where safety becomes much more subtle. A safe AI system is not just a smart model with a good heart, so to speak. It is a system whose capabilities are expressed in the right context, with the right controls, at the right time, for the right purpose. That starts to sound a lot like how living systems work.
The public conversation about AI safety often collapses into extremes. Either the risks are dismissed as hype, or they are treated like science fiction doom. Both views miss the more important point. The real challenge is developmental. Powerful AI systems will not become safe because of one magical filter, one constitutional prompt, or one policy document. They become safer or less safe through the full process that shapes them: the data they absorb, the objectives they optimize, the feedback they receive, the tools they can access, the environments they operate in, and the institutions that supervise them.
That is why this human analogy matters so much. It gives us a more grounded model. It tells us not to rely on slogans. Not to rely only on outer guardrails. Not to trust safety that exists only in the marketing copy. It tells us to think like builders of developmental systems.
What kind of base patterns are we feeding into the model? What behaviors are we rewarding? What kinds of self-correction are we teaching? What tools can the model use? What happens when uncertainty rises? What happens when the model is pressured, manipulated, or tempted into harmful shortcuts? What institutions surround it when it is deployed into the real world?
These are not philosophical side questions. They are the central engineering questions. And they become much easier to understand once you borrow the human frame.
The point of all this is not to blur the line between humans and machines. The point is that the human story gives us the best intuition we have for how intelligence becomes safe enough to live among others. Humans did not become cooperative through raw intelligence alone. We built layers around intelligence. Inheritance. Learning. Reward. Correction. Social pressure. Institutions. Consequence. Accountability. That is how we got from raw impulse to civilization.
AI will need the same layered seriousness. Pretraining gives the base map. Post-training shapes the behavior. Reinforcement strengthens some paths and weakens others. Guardrails create boundaries. Monitoring catches drift. Governance creates accountability. Human judgment remains the final backstop. The future of AI alignment should look less like installing a lock and more like raising a mind inside a society. That is the light-bulb moment.

AI safety is not one guardrail. It is the whole upbringing.